評估模型
機器學習模型就像是一個需要不斷練習的學生,我們需要適當的方法來評估它的學習成果。今天讓我們來了解如何科學地評估一個模型的表現。
何為訓練集、驗證集、測試集
在開始解釋不同的數據集之前,我們先來理解兩種重要的參數:
權重參數(weight parameter):
- 這是模型通過學習自動調整的參數
- 就像學生在解題過程中學到的解題技巧
超參數(hyperparameter):
- 這是我們需要手動設置的參數
- 就像是老師設定的學習進度和難度
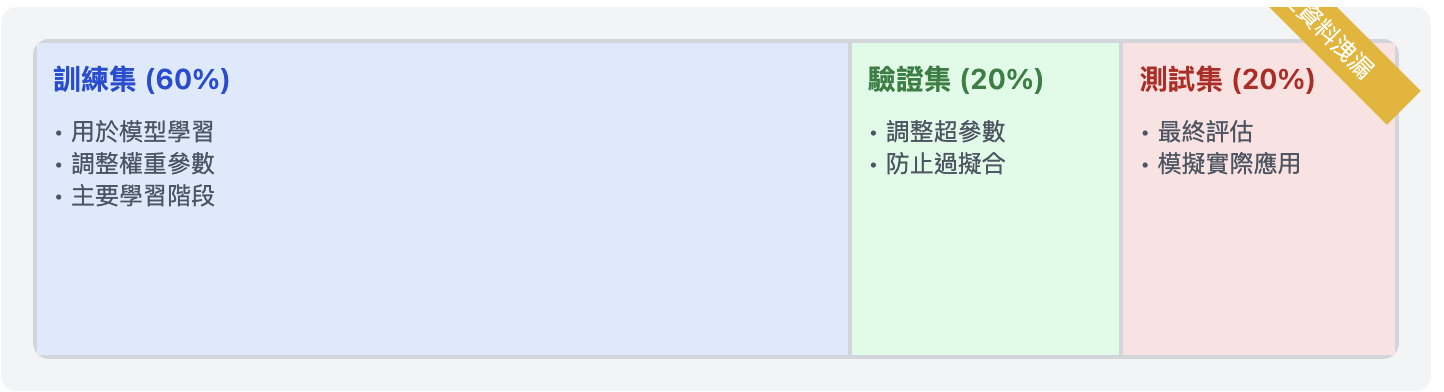 數據集的三個部分各自扮演著不同的角色:
數據集的三個部分各自扮演著不同的角色:
訓練集:
- 用於模型的主要學習階段
- 調整權重參數
- 佔總數據量約 60-80%
驗證集:
- 用於調整超參數
- 幫助我們選擇最佳的模型配置
- 佔總數據量約 10-20%
測試集:
- 用於最終的模型評估
- 模擬真實世界的應用場景
- 佔總數據量約 10-20%
資料洩漏(information leak):
- 指測試資料的訊息不當地影響了模型訓練,就像是考試前看到了試題,會導致模型評估結果不可靠。
進階驗驗方法
- 當資料不足時,就可能要採用一些進階方法來處理,以下介紹三種經典方法:
簡單拆分驗證(simple holdout validation):
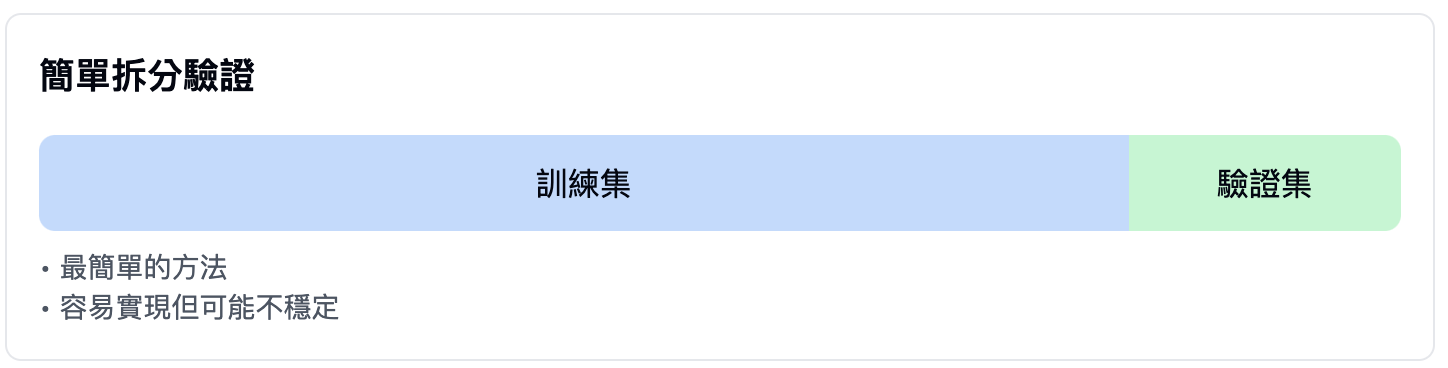
- 最基本的方法
- 直接將數據分為訓練集和驗證集
- 優點:簡單、快速
- 缺點:結果可能不穩定
K折驗證(k-fold validation):
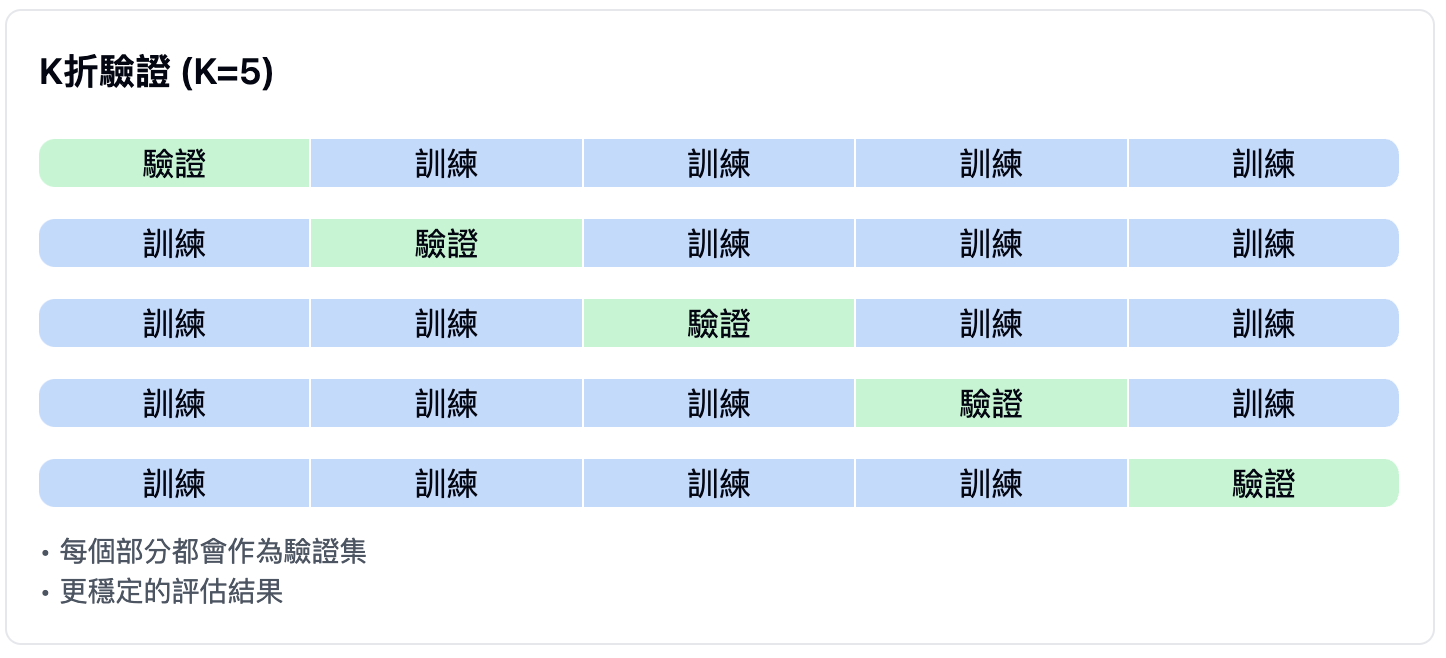
- 將數據分為K個相等的部分
- 每次使用其中一部分作為驗證集
- 重複K次,取平均結果
- 優點:更穩定的評估結果
- 常用的K值為5或10
K折加洗牌驗證(Iterated K-fold validation with shuffling):
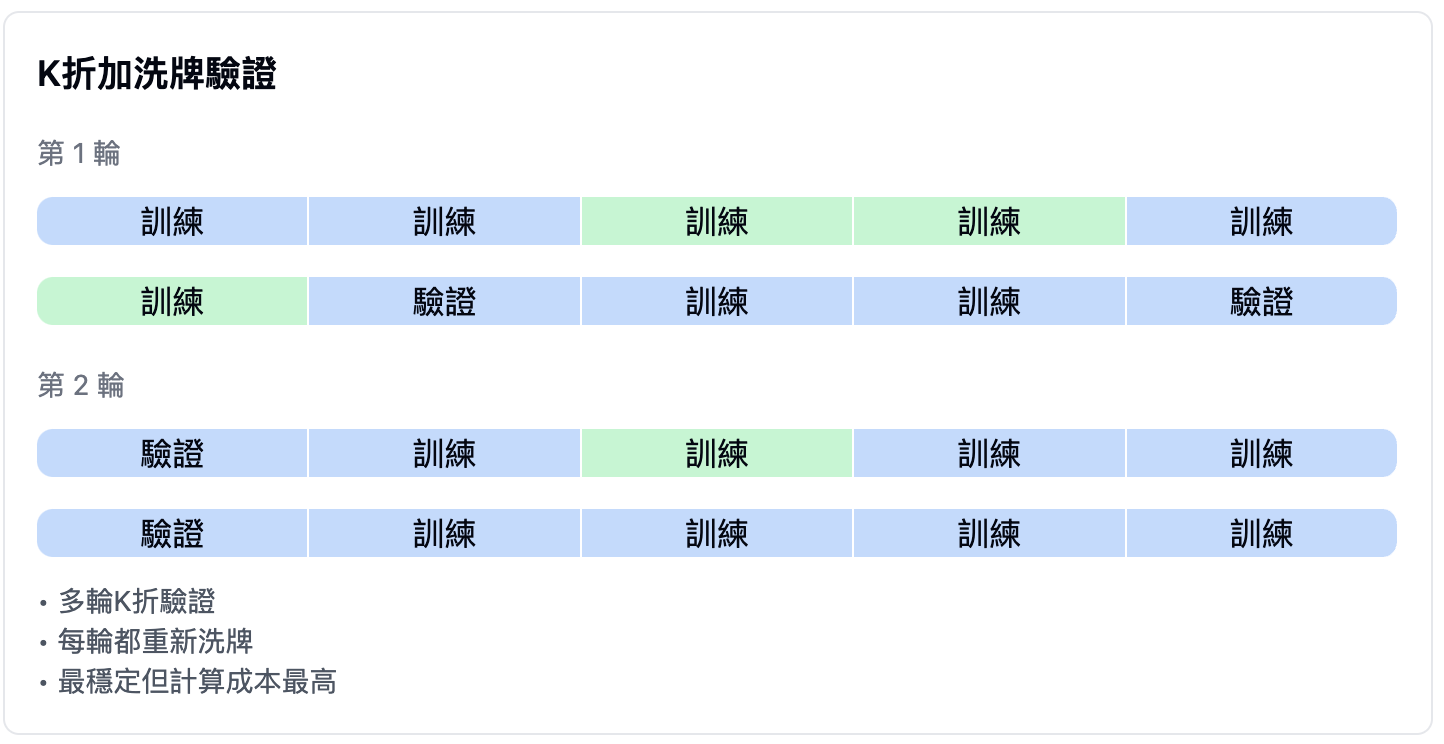
- 在K折驗證的基礎上增加多輪重複
- 每輪都重新打亂數據順序
- 優點:最穩定的評估結果
- 缺點:計算成本較高
基準線(Baseline)
- 在評估模型是否有效時,可以在訓練前先設定一個基準線,而機器學習的目的在於打敗基準線。
- 以 mnist 來說,假設
0~9的 labels 數大致相同,則盲猜能達到的準確度應該相當於期望值,也就是 \(\frac{1}{10}\)。換句話說,我們可以將基準線訂為 10%,如果模型做出來的準確度比 10% 還要差,那還不如盲猜呢! - 以 IMDB 為例,準確度至少要差過 50%,因為只有正負評論兩個類別。
- 在路透社的文章分類目,準確度至少要超過 18~19%,因為有樣本不平衡的問題。
- 以工廠為例,可能每 10000 張缺陷照片會出現 1 張是有害缺陷,模型若是判斷全部 10000 張都是無害的,那正確率也有 \(\frac{9999}{10000}\),也就是 99.99%,但這代表抓不到有害缺陷,那就代表這個模型是無效的,所以當資料不平衡時,會產生很大的問題。
評估模型時的注意事項
- 資料代表性(data representation):
- 我們希望訓練集和測試集都有一定的代表性,足以反映手邊的資料分佈。
- 準例來說,我們在做選舉民意調查時,我們都用打市話來進行市調,做為訓練集,然後收集手機民調,做為測試集。由於市話與手機的使用族群不相同,可能導致了訓練集與測試集的代表性都不足。
- 故我們通常需要對資料進行洗牌(shuffle),使訓練集與測試集都具備一定的代表性。
- 時間的方向性(the arrow of time):
- 如果我們想要從過去資料來預測未來狀態,如天氣、股票走勢,則不該隨意將資料打亂並拆分成訓練集和測試集。
- 具備時間性的資料被打亂,會造成時間漏失(temporal leak),而造成時序錯位。
- 在進行具時間性的預測時,應確保測試資料的發生時間是在訓練資料之後。
- 資料中的重複現象:
- 如果資料出現兩次,隨意打亂,可能會造成資料同時出現在訓練集與測試集中,那麼就相當於資料洩漏(information leak),這樣訓練出來的模型將不可信。