Convolutional Neural Network(CNN)
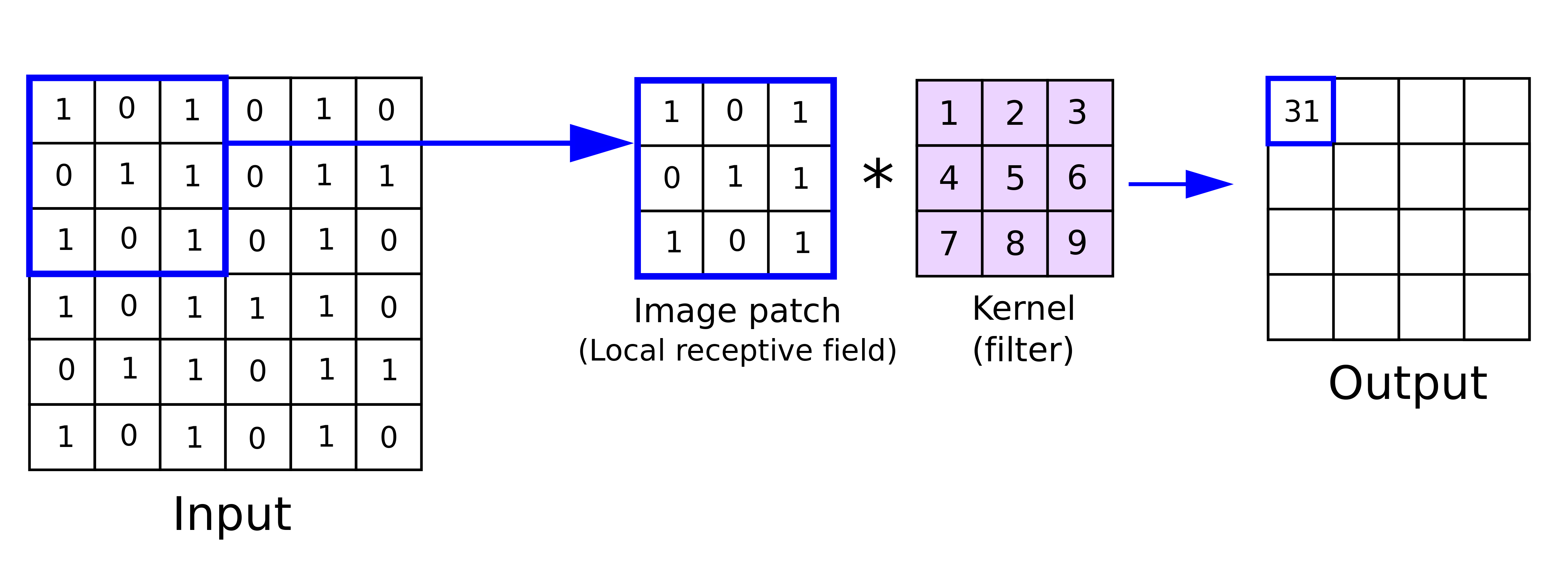
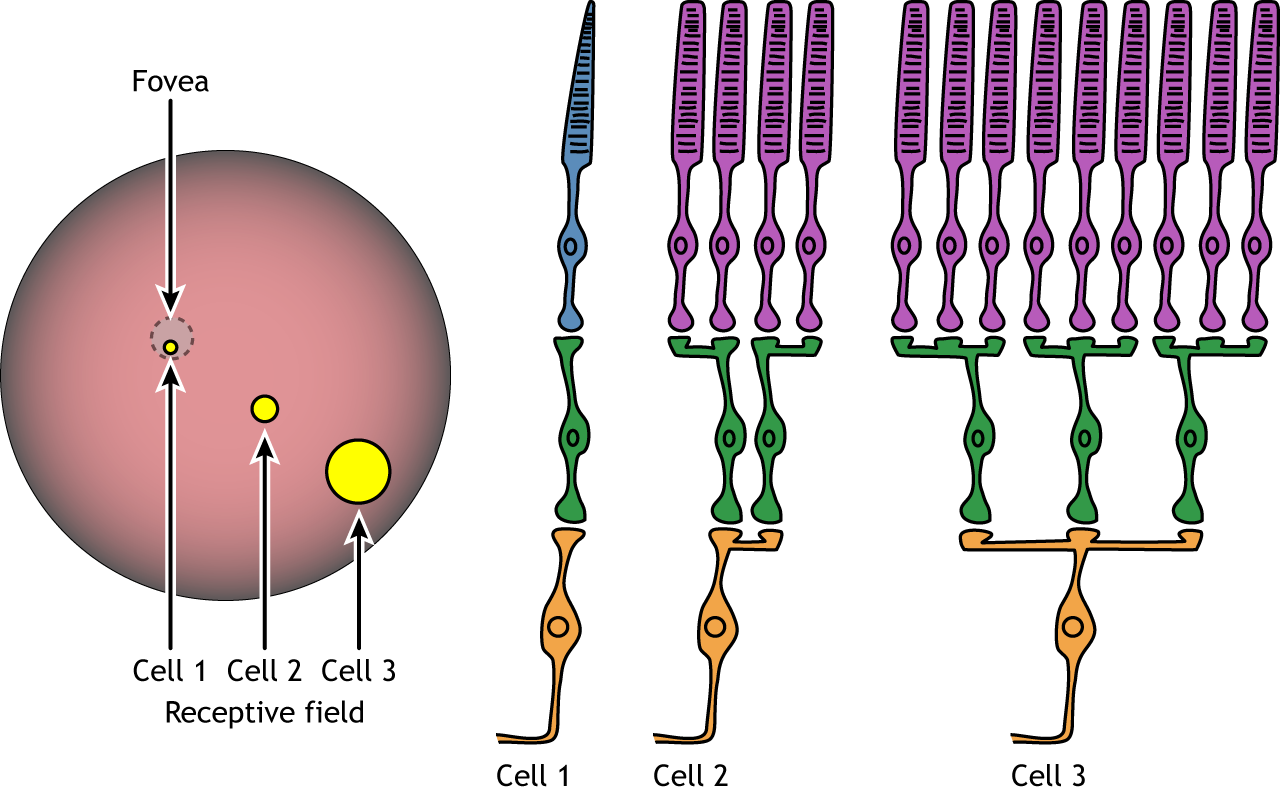
- 卷積神經網路有點像是在模仿人類判讀圖片的過程,我們在判斷一張圖是什麼時,會專注在看圖中的某些區域中(receptive field)的某個特徵,kernel(filter) 就像是偵測某一個 patten 是否存在的 neuron。
- 相較於一般的 fully connected(dense layer),Convolutional layer 就是利用兩個特性
- receptive field: 只識別小區域的訊息
- parameter sharing: 共享參數
建構 convnet
- 我們來建構一個簡易的小型卷積神經網路(convnet)
from tensorflow import keras
from tensorflow.keras import layers
def get_cnn_model():
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
model = get_cnn_model()
model.summmary()
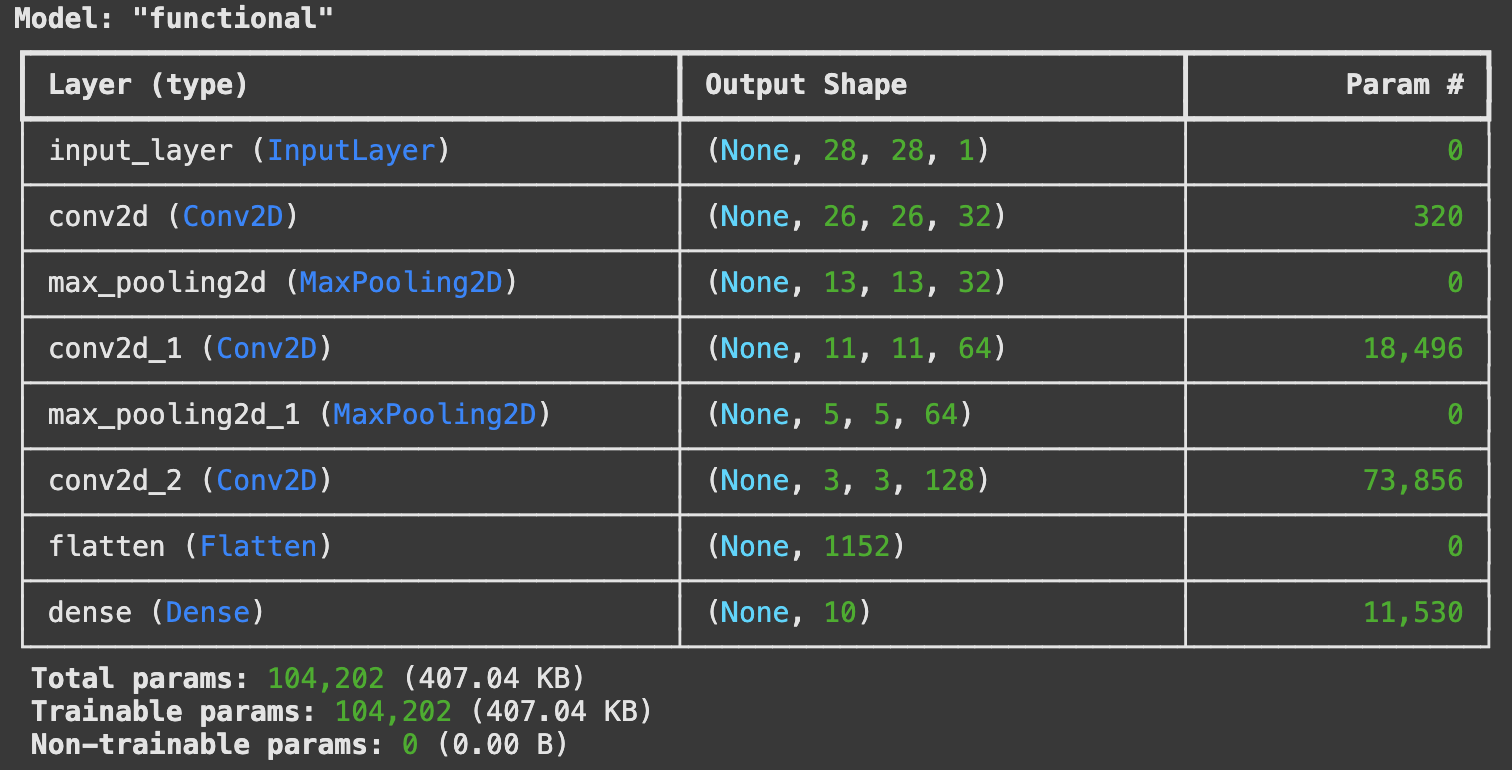
透過圖解,我們可以知道 CNN 中 layer shape 是怎麼變化的。
而參數量是通過下面的方式透算的:(其中 1 是 bias)。
- 其中
max_pooling與flatten都是沒有參數的,max_pooling類似於max_out是將 featrue_map 以指定的pooling手法進行 sampling。(事實上也可以不做或是改用 avg_pooling 等其它手法)。而flatten可以想成是 reshape 成 1D 張量的方法,為了讓其可以作為 Dense layer 的 input。 $$ \text{參數量}=(\text{kernel\_size}^2 \times \text{input\_channels} + 1) × \text{output\_channels} $$
- 其中
用 MNIST 影像訓練 convnet
from tensorflow.keras.datasets import mnist
model = get_cnn_model()
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
- 用測試資料來評估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accurarcy: {test_acc:.3f}")
> Test accurarcy: 0.992
卷積層的功用
卷積層(convolutional layer) 的兩個特性
- receptive field: 只識別小區域的訊息
- parameter sharing: 共享參數
- 使他提供了兩項有趣的性質:
- 平移不變性(translation invariant): 任一位置識別到相同 pattern 時,在 fully connected layer 中需要重新學習,但在卷積層因為參數共享的關係不需要重新學習,所以卷積神經可以更有效率的處理影像資料,進而在較少訓練樣本下培養出普適化的能力。
- 有學習到 pattern 中的空間階層架構(spatial hierarchies of patterns): 就像是我們先從小物件偵測,進而組成局部物件,然後進階物件。
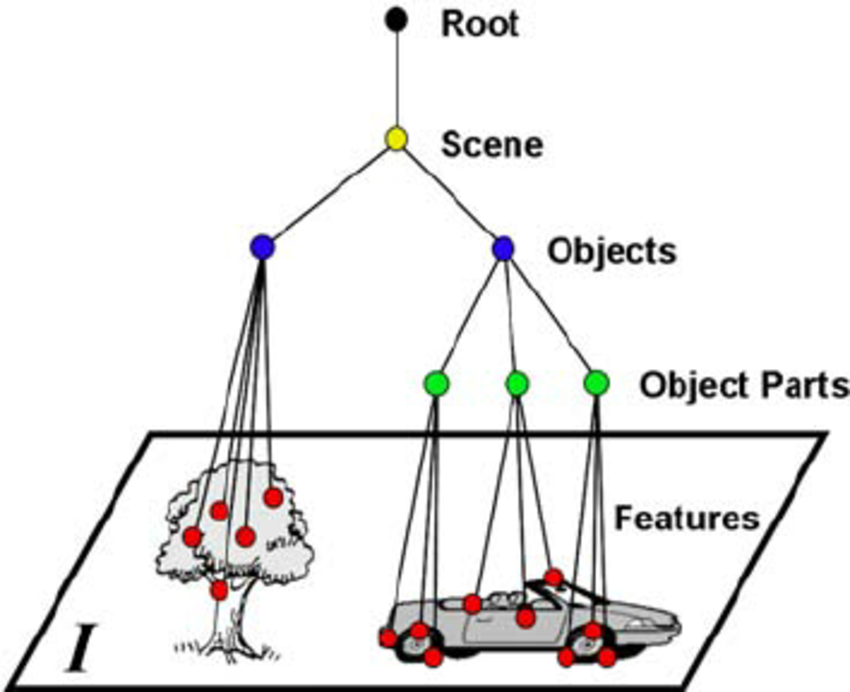
卷積神經網路所運算的 3D 張量,稱為特徵圖(feature maps),包含兩個空間軸與一個深度(channel)。
- 以黑白影像來說,有 1 個 channels。
- 以 RGB 影像來說,有 3 個 channels。
以下是使用客製化的 filter,來對 mnist 資料集做 filter 運算後得到的 response maps

邊界效應,使用 kernel 來 filtering 圖像,在邊緣的部分會產生部分損失,這個部分可以通過
padding的技巧來克服,其中 padding 的量可以是0或是平均值。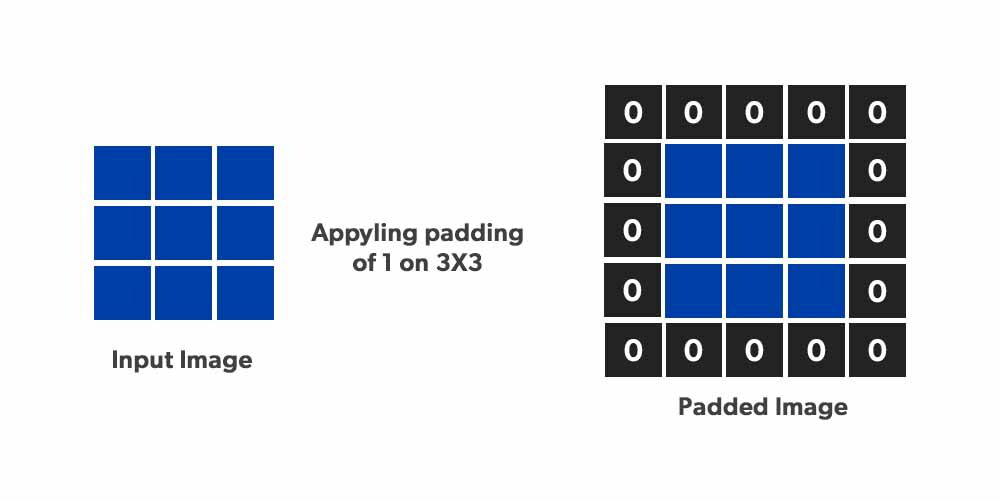
strides 代表 kernel 滑動的 step,實務上很少使弿 strided onvolution,也就是把 stides 設大於 1,要減少採樣數以減少計算量,可以通過另一個手法
max_pooling。
最大池化(max pooling)
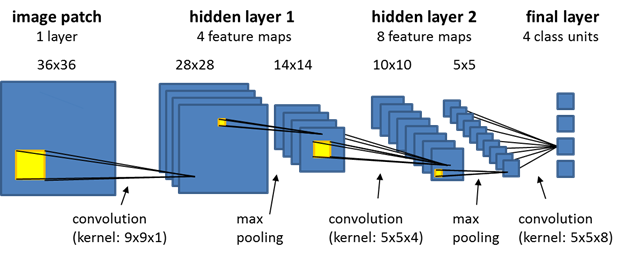
- max pooling 是透過對 feature maps 取 n*n 中的最大值,做為下一層的輸出,以 2 * 2 的 max_pooling 為例,原本 26 * 26 的 feature map 就會被轉為 13 * 13 的 featrue map。
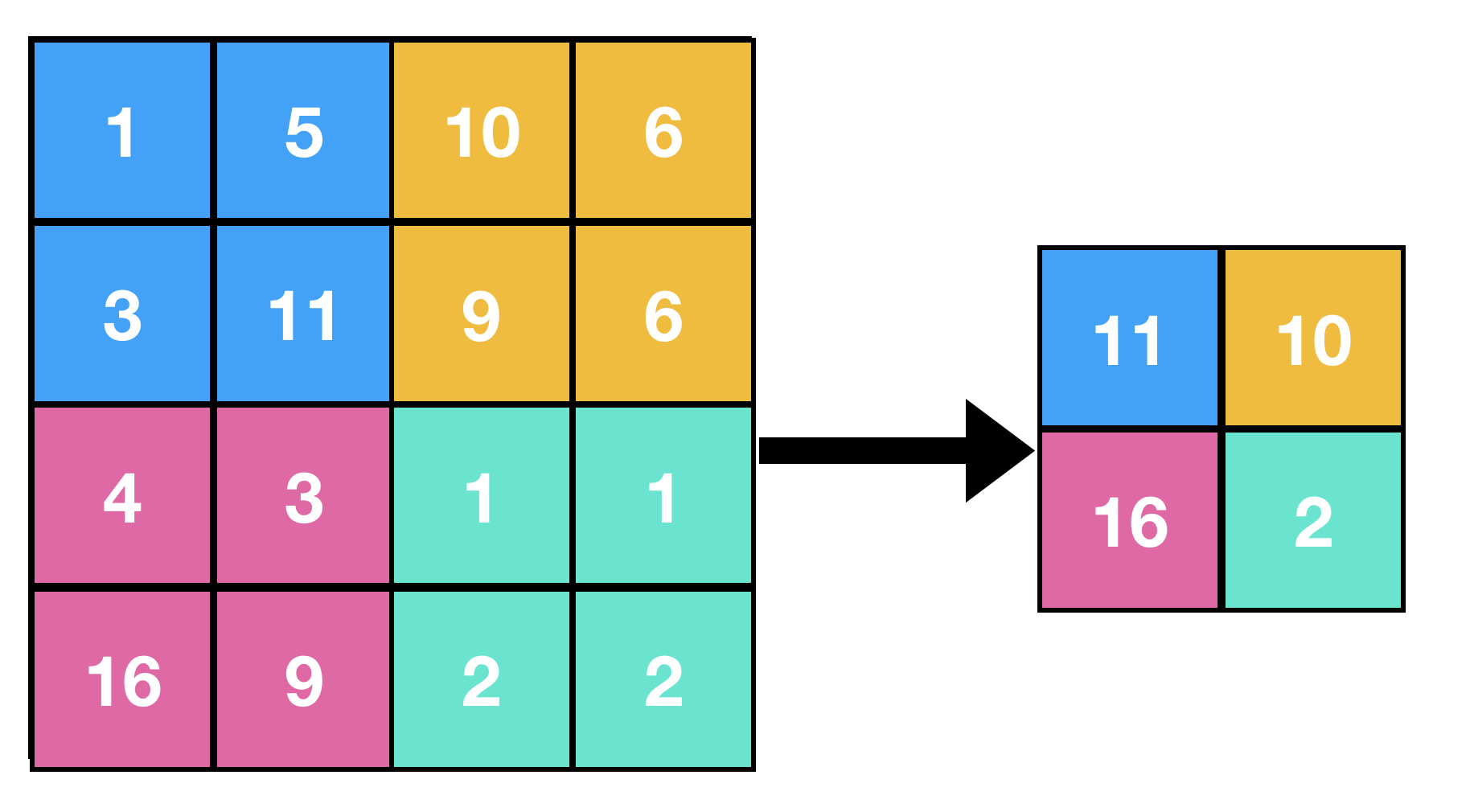
- max pooling 達到的效果有:
- 降採樣,可以減少所需的計算量。
- 增加學習特徵的空間層次。(在第一層,考慮到的 receptive field 只有 3*3,但透過 max pooling,第一層就可以放大到原圖的 7 * 7)。