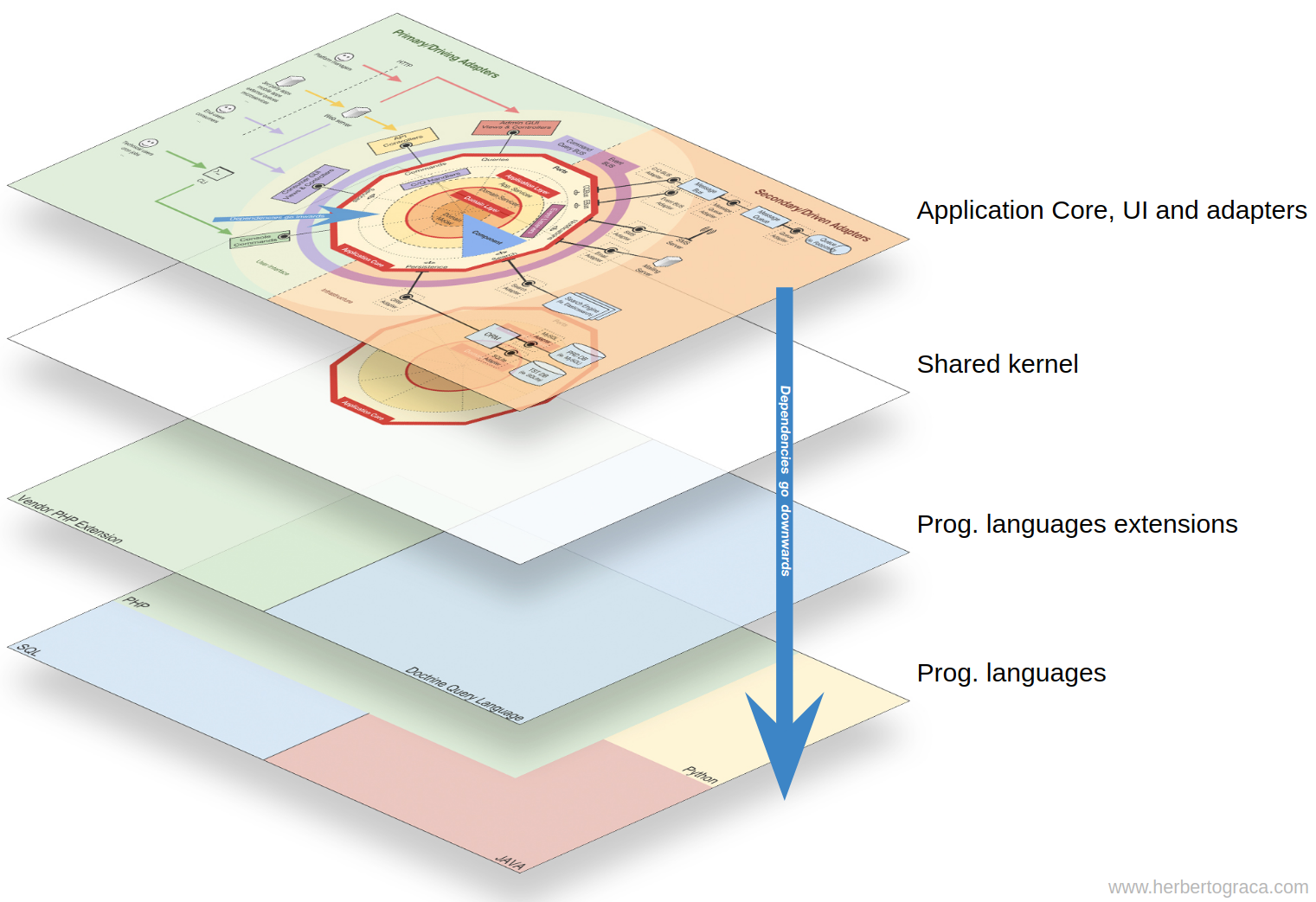
本文是介紹我如何將 DDD, Hexagonal, Onion, Clean, CQRS Architecture 等架構概念整合在一起,我將它命名為 Explicit Architecture。上述的概念基本上都是通過了市場的試驗,並在許多高要求的平台上被應用。
系統的基本組件
首先回顧 EBI 與 Ports & Adapter 架構。這兩種架構都明確區分了哪些程式碼是應用程式的內部,哪些是外部,以及哪些是連接內部和外部的程式碼。
Ports & Adapters 明確地定義出了系統的三個部分:
- 使用者介面 (User Interface, UI)
- 商業邏輯(business logic)、應用程式核心(application core)
- 基礎設施(Infrastructure),如 DB、搜尋引擎或第三方API等工具。
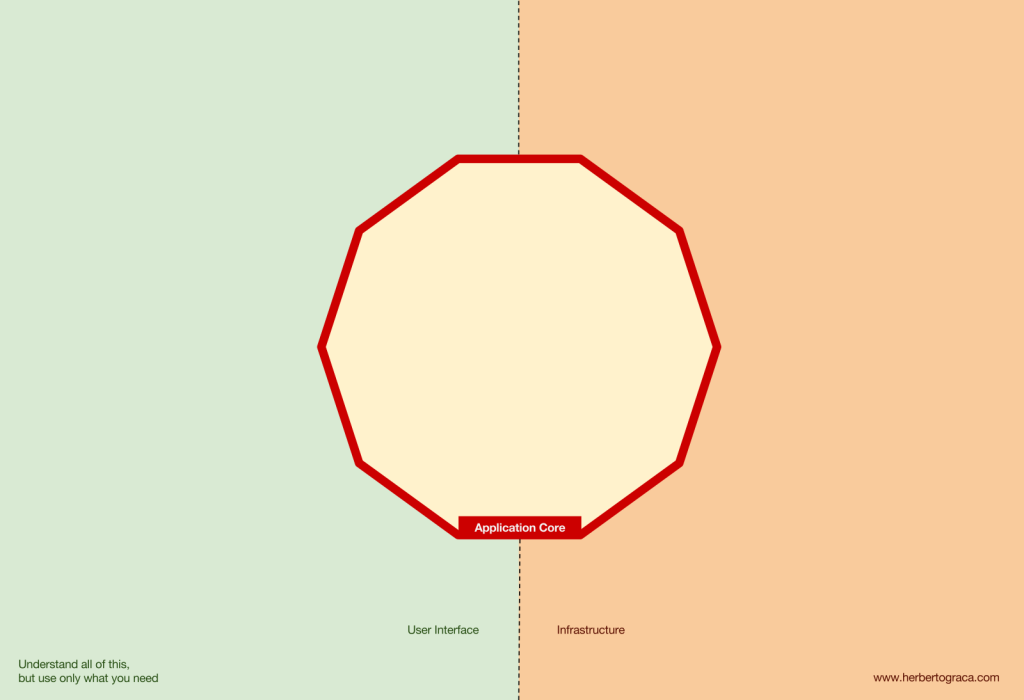
我們真正應該關心的是應用程式的核心,這是讓我們的程式碼能夠完成其應有功能的程式碼。它可能會使用多種 UI(網頁、手機、CLI、API 等等),但實際執行工作的程式碼是相同的,並位於應用程式的核心,觸發它的 UI 實際上並不重要。
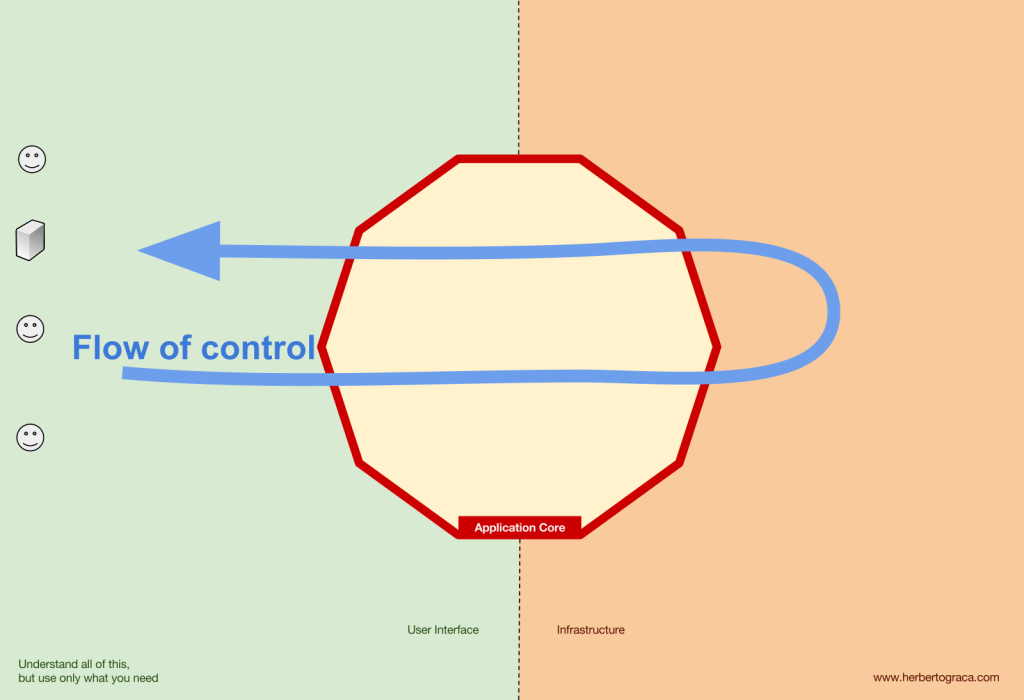
一個典型的應用程式流程從 UI 的程式碼開始,經過應用程式核心到基礎設施程式碼,再回到應用程式核心,最後將回應傳遞給 UI。
工具 Tools
工具指的是那些遠離我們系統核心程式碼,但為我們應用程式所用的工具,例如,DB、搜尋引擎、網頁伺服器或 CLI 控制台(儘管後兩者也是交付機制)。
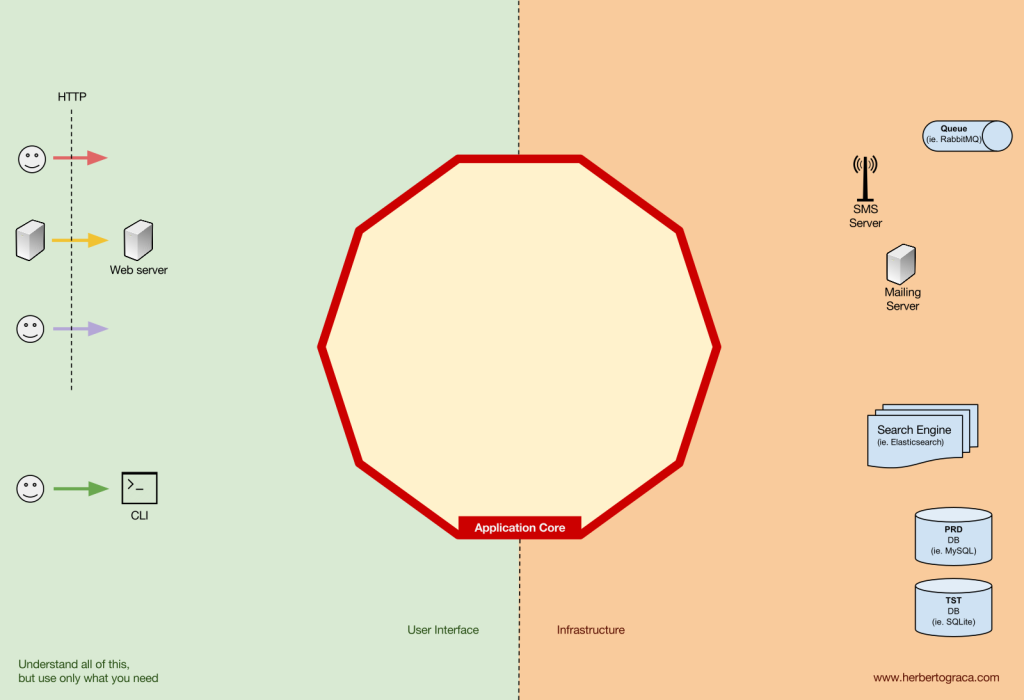
雖然將 CLI 與 DB 分類在一起可能有些奇怪,儘管它們有不同的目的,但實際上它們都是應用程式使用的工具。關鍵的區別在於,CLI 和網頁服務器用於告訴我們的應用程式做些什麼,而 DB 則由我們的應用程式告訴它做些什麼。這是一個非常重要的區別,因為它對我們如何建構連接這些工具與應用程式核心的程式碼有著強烈的影響。
將工具和傳遞機制連接到應用程式核心
連接工具與應用程式核心的程式碼單元被稱為適配器(Ports & Adapters Architecture),適配器實現了將業務邏輯與特定工具進行通訊。
告知我們應用程式應該做什麼事的適配器稱為 Primary 或 Driving Adapters;
被我們應用程式告知應該做什麼事的適配器稱為 Secondary or Driven Adapters。
埠 Ports
然而,這些適配器並非隨機創建的,它們是為了適應應用程式核心的一個非常特定的入口點,也就是埠。埠不過是一種規範,說明工具如何使用應用程式核心,或者說明它如何被應用程式核心使用。在大多數語言中,以其最簡單的形式,這種規範,或埠,即是一個介面(interface),但實際上可能由多個介面和 DTO 組成。
需要注意的是,埠(介面)屬於業務邏輯內部,而適配器則屬於外部。要讓這種模式正常運作,最重要的是要根據應用核心的需求來創建埠,而不僅僅是模仿工具的 API。
主要適配器 Primary or Driving Adapters
主要或驅動適配器包裹在一個埠上,並使用它來指示應用程式核心該做什麼。他們將來自傳遞機制的任何內容轉換為應用程式核心中的方法調用。
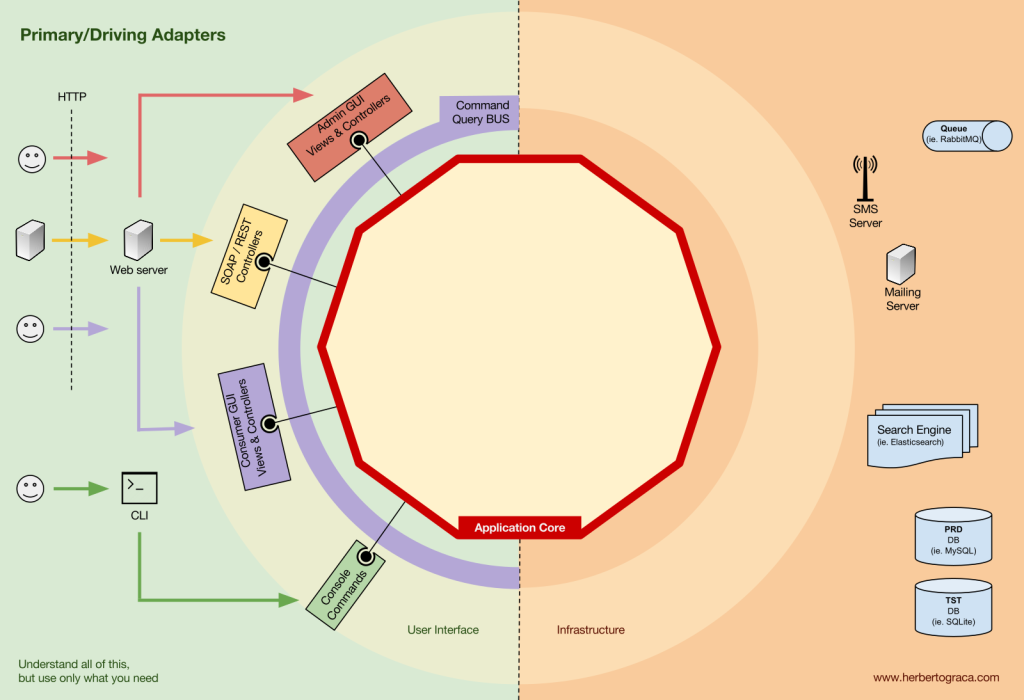 換句話說,我們的驅動適配器是控制器或控制台命令,它們在建構子中注入了一些物件,這些物件的類別實現了控制器或控制台命令所需的介面(埠)。
換句話說,我們的驅動適配器是控制器或控制台命令,它們在建構子中注入了一些物件,這些物件的類別實現了控制器或控制台命令所需的介面(埠)。
在一個更具體的例子中,埠可以是控制器所需的服務介面或儲存庫介面。然後,將服務、儲存庫或查詢的具體實現注入並在控制器中使用。
或者,一個埠可以是命令總線或查詢總線介面,在這種情況下,命令或查詢總線的具體實現將被注入到控制器中,然後控制器構建一個命令或查詢並將其傳遞給相關的總線。
次級適配器 Secondary or Driven Adapters
與 Driver Adapters 不同的是,Driven Adapters 實現了一個埠、一個介面,然後被注入到應用核心中,無論該埠在何處被需要(類型提示)。Driven Adapter 是包裹在埠周圍的。
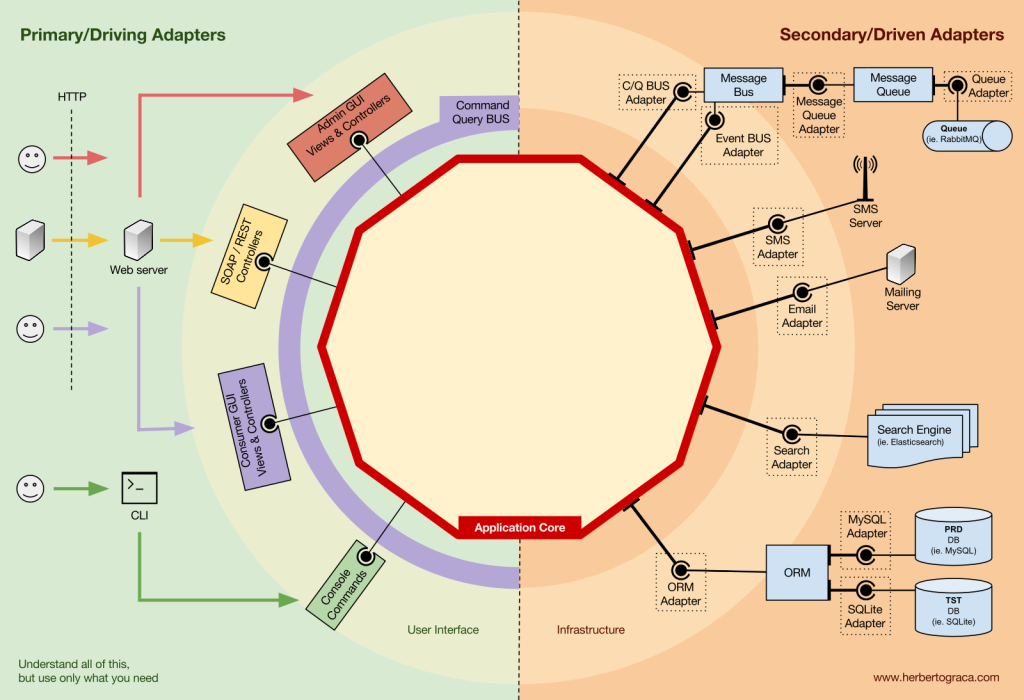
例如,假設我們有一個需要持久化數據的初級應用程式。因此,我們創建了一個符合其需求的持久化介面,該介面有一個用於保存數據陣列的方法,以及一個根據ID刪除表中行的方法。從那時起,無論我們的應用程式何時需要保存或刪除數據,我們都會在其構造器中需要一個實現我們定義的持久化介面的物件。
現在我們將創建一個專門針對 MySQL 的適配器,該適配器將實現該介面,它將具有保存陣列和在表中刪除一行的方法,我們將在需要持久化介面的任何地方注入它。
如果我們在某一點決定更換 DB vendor,比如說改用 PostgreSQL 或 MongoDB,我們只需要創建一個實現持久性介面並專門針對 PostgreSQL 的新適配器,並將新適配器取代舊的適配器即可。
控制反轉 Inversion of control
關於這種模式的特點是,適配器依賴於特定的工具和特定的端口(通過實現一個介面)。但是,我們的業務邏輯只依賴於端口(介面),該介面被設計來滿足業務邏輯的需求,所以它並不依賴於特定的適配器或工具。
這意味著依賴性的方向是朝向中心,這是在架構層面上的控制反轉原則。
儘管如此,再次強調,最重要的是要根據應用程式核心的需求來創建端口,而不僅僅是模仿工具的API。
應用核心組織
洋蔥架構採用了DDD層並將其融入到Ports & Adapters架構中。這些層旨在為業務邏輯,即Ports & Adapters“六邊形”的內部,帶來一些組織。就像在Ports & Adapters中一樣,依賴方向是朝向中心。
應用層 Application Layer
使用案例(Usecases)是我們的應用程式核心中可以由一個或多個使用者介面觸發的流程。例如,在CMS中,我們可能有實際的應用程式UI供一般用戶使用,另一個獨立的UI供CMS管理員使用,另一個CLI UI,以及一個網路API。這些UI(應用程式)可以觸發特定於其中一個或由多個重複使用的使用案例。
使用案例是在應用層中定義的,這是由DDD提供並被洋蔥架構使用的第一層。
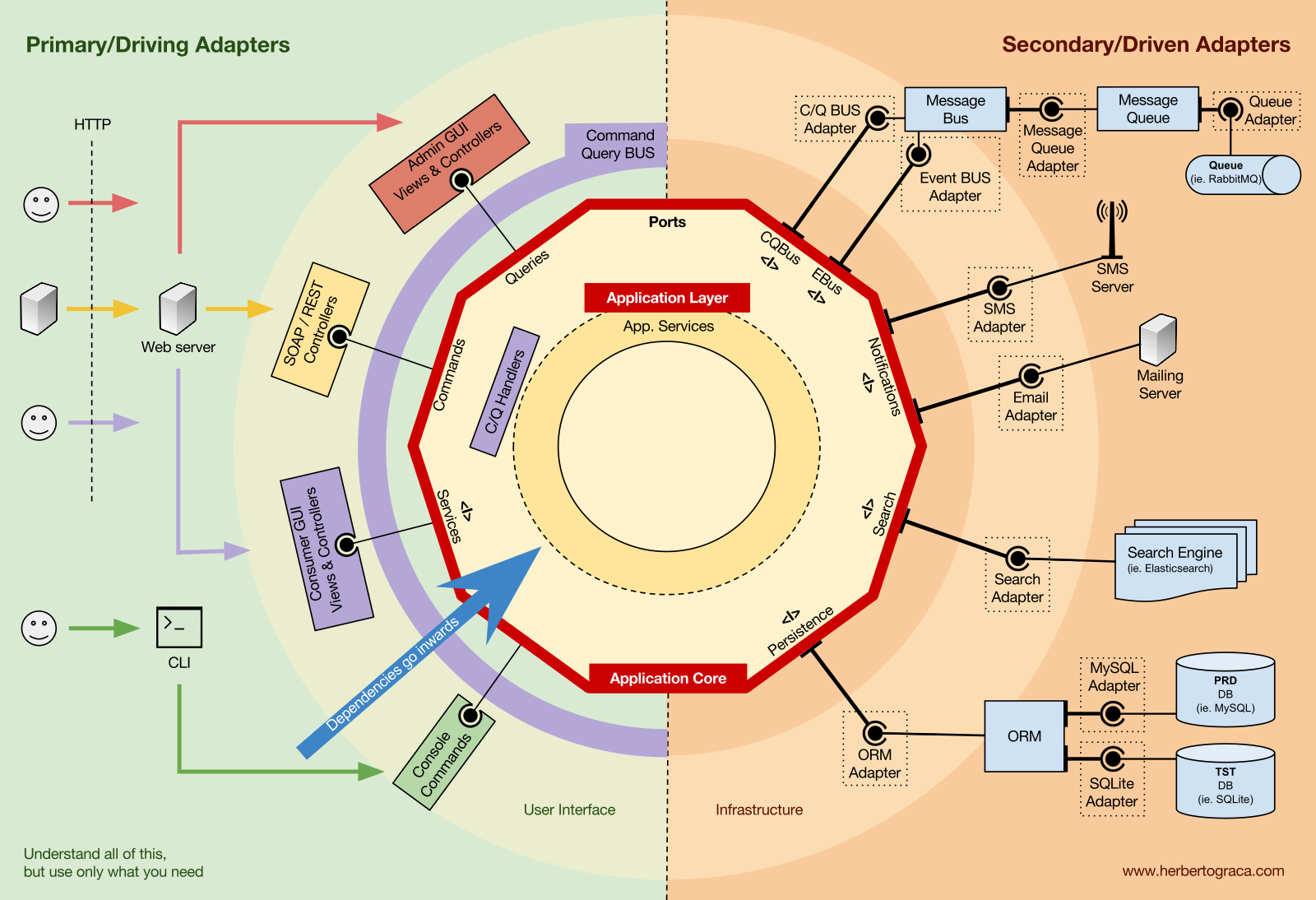
這一層包含了應用服務(及其介面)作為門面,但它也包含了端口和適配器介面(端口),其中包括 ORM、搜尋引擎介面、訊息介面等等。在我們使用命令總線和/或查詢總線的情況下,這一層就是命令和查詢的相應處理器所在的地方。
應用服務和/或命令處理器包含了展開用例、業務流程的邏輯。通常,他們的角色是:
- 使用資料庫來尋找一個或多個實體;
- 告訴那些實體去做一些領域邏輯;
- 並利用資料庫再次保存實體,有效地儲存了數據變更。 (口訣:查改存推)
命令處理器可以用兩種不同的方式來使用:
- 他們可以包含實際的邏輯來執行用例;
- 他們可以被用作我們架構中的純粹線路部分,接收一個指令並觸發存在於應用服務中的邏輯。
選擇使用哪種方法取決於情境,例如:
- 我們是否已經有了應用服務,並且現在正在添加命令總線?
- 命令總線是否允許指定任何類別/方法作為處理器,或者它們需要擴展或實現現有的類別或介面?
這一層也包含了應用程式事件的觸發,這些事件代表了某個用例的結果。這些事件會觸發一些側效應邏輯,例如發送電子郵件、通知第三方API、發送推送通知,甚至開始屬於應用程式不同組件的另一個用例。
領域層 Domain Layer
更深入地,我們有領域層。這一層的對象包含數據以及操作該數據的邏輯,這些都是特定於領域本身的,並且它們獨立於觸發該邏輯的業務流程,它們是獨立的,並且完全不知道應用層的存在。
領域服務 Domain Service
如我上述所提,應用服務的角色是:
- 使用資料庫來尋找一個或多個實體
- 告訴那些實體去做一些領域邏輯;
- 並利用資料庫再次保存實體,有效地儲存了數據變更。
然而,有時我們會遇到涉及不同實體的一些領域邏輯,無論是相同類型與否,我們覺得這些領域邏輯並不屬於實體本身,我們認為這些邏輯並非他們的直接責任。
所以,我們的第一反應可能是將該邏輯放在實體之外,放在應用服務中。然而,這意味著該領域邏輯將無法在其他用例中重複使用:領域邏輯應該遠離應用層!
解決方案是創建一個領域服務,其角色是接收一組實體並對其執行一些業務邏輯。領域服務屬於領域層,因此它對應用層中的類別一無所知,例如應用服務或存儲庫。另一方面,它可以使用其他領域服務,當然,也可以使用領域模型對象。
領域模型 Domain Model
位於最中心的,不依賴於其外的任何事物,就是領域模型,其中包含代表領域中某些事物的業務物件。這些物件的例子首先是實體,但也包括價值物件、枚舉以及在領域模型中使用的任何物件。
領域模型也是領域事件的所在地。當特定的數據集發生變化時,這些事件就會被觸發,並且它們會攜帶這些變化。換句話說,當實體發生變化時,就會觸發一個領域事件,並且它會攜帶變化屬性的新值。例如,這些事件非常適合用於事件源。
組件 Components
到目前為止,我們一直在根據層次對程式碼進行分離,但這只是細粒度的程式碼分離。粗粒度的程式碼分離至少同樣重要,它涉及到根據子域和有界上下文對程式碼進行分離,遵循 Robert C. Martin 在尖叫架構中表達的想法。這通常被稱為「按功能打包」或「按組件打包」,與「按層打包」相對,Simon Brown 在他的部落格文章「按組件打包和與架構對齊的測試」中對此解釋得相當清楚。
根據 Simon Brown 關於按組件打包的圖表,將其改為以下內容:
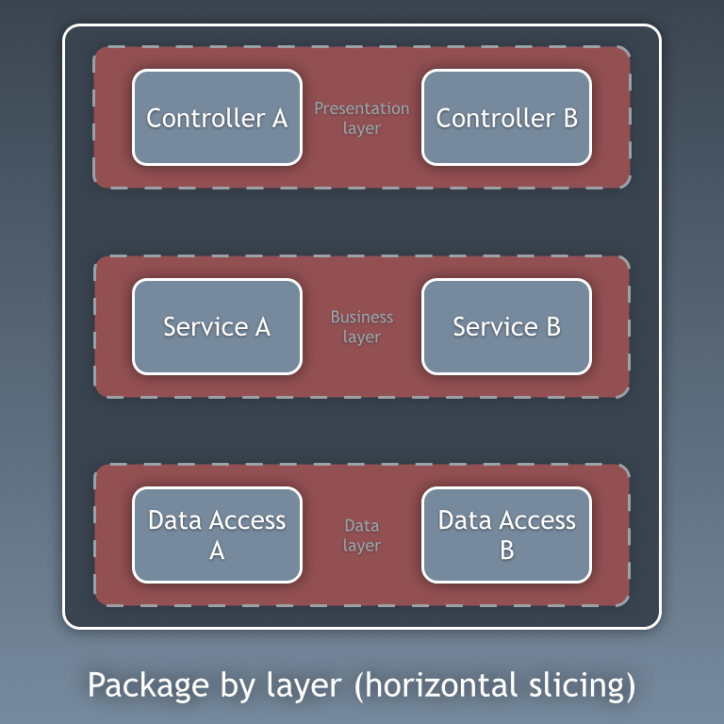
這些程式碼部分是橫跨我們之前描述的各層,它們是我們應用程式的組件。組件的例子可以是身份驗證、授權、計費、用戶、評論或帳戶等,但它們總是與領域相關。像授權和/或身份驗證這樣的有界上下文應被視為我們創建適配器並隱藏在某種端口後的外部工具。

解耦組件
就像細緻的程式碼單元(類別、介面、特性、混入等),粗粒度的程式碼單元(組件)也從低耦合和高內聚中獲益。
為了解耦類別,我們利用依賴注入,將依賴性注入到類別中,而不是在類別內實例化它們,並且透過依賴反轉,讓類別依賴於抽象(介面和/或抽象類別)而非具體類別。這意味著依賴類別對它將要使用的具體類別一無所知,它對其所依賴的類別的完全限定類別名稱沒有任何參考。
同樣地,完全解耦的組件意味著一個組件對任何其他組件沒有直接的認識。換句話說,它對來自其他組件的任何細粒度代碼單元都沒有參考,甚至連介面都沒有!這意味著依賴注入和依賴反轉不足以解耦組件,我們將需要某種形式的架構構造。我們可能需要事件,共享內核,最終一致性,甚至是一個發現服務!
觸發其它組件中的邏輯
當我們的其中一個組件(組件B)需要在另一個組件(組件A)發生某事時做些什麼,我們不能簡單地從組件A直接呼叫組件B中的類別/方法,因為這樣會使A與B產生耦合。
然而,我們可以讓A使用事件分發器來分發一個應用程序事件,該事件將被傳遞給任何正在監聽它的組件,包括B,並且B中的事件監聽器將觸發所需的動作。這意味著組件A將依賴於一個事件分發器,但它將與B解耦。
然而,如果事件本身“存在於”A,這意味著B知道A的存在,它與A有所連結。為了消除這種依賴性,我們可以創建一個包含一套應用程式核心功能的庫,這些功能將在所有組件之間共享,這就是所謂的共享核心。這意味著,各組件都將依賴於共享核心,但它們將彼此解耦。共享核心將包含如應用程式和領域事件等功能,但它也可以包含規範對象,以及任何有意義的共享內容,但要記住,它應盡可能地保持最小,因為對共享核心的任何更改都將影響應用程式的所有組件。此外,如果我們有一個多語系統,比如說一個由不同語言編寫的微服務生態系統,那麼共享核心需要是語言無關的,以便所有組件都能理解,無論它們是用什麼語言編寫的。例如,共享核心將不包含事件類,而是包含事件描述(即。 名稱、屬性,甚至可能是方法(雖然這些在規範對象中可能更有用)在一種不可知的語言如JSON中,以便所有組件/微服務都可以解釋它,甚至可能自動生成他們自己的具體實現。在我的後續文章中閱讀更多關於這個的信息:不僅僅是同心層。
這種方法適用於單體應用程式和分散式應用程式,如微服務生態系統。然而,當事件只能異步傳遞時,對於需要立即觸發其他組件邏輯的情境,這種方法將不足夠!組件A將需要直接對組件B進行HTTP呼叫。在這種情況下,為了讓組件解耦,我們將需要一個發現服務,A將詢問它應該將請求發送到哪裡以觸發所需的動作,或者將請求發送到發現服務,該服務可以將其代理到相關服務,並最終將回應返回給請求者。這種方法將使組件與發現服務耦合,但將使它們彼此解耦。
從其它組件獲取數據
在我看來,一個組件是不被允許改變它並不“擁有”的數據,但它可以查詢和使用任何數據。
組件間共享的數據儲存
當一個組件需要使用屬於另一個組件的數據時,例如,計費組件需要使用屬於帳戶組件的客戶名稱,計費組件將包含一個查詢對象,該對象將查詢數據存儲以獲取該數據。這僅僅意味著計費組件可以知道任何數據集,但它必須將其並不“擁有”的數據作為只讀方式,通過查詢來使用。
根據組件分離的數據儲存
在這種情況下,相同的模式仍然適用,但我們在數據存儲層面上有更多的複雜性。擁有自己數據存儲的組件意味著每個數據存儲包含:
- 一組數據,它擁有並且是唯一被允許更改的,使其成為唯一的真理來源;
- 一組數據,這是其他組件數據的副本,它無法自行變更,但對於組件功能來說是必要的,並且每當在擁有者組件中變更時,都需要進行更新。
每個組件都會從其他組件中創建所需數據的本地副本,以便在需要時使用。當擁有該數據的組件中的數據發生變化時,該擁有者組件將觸發一個攜帶數據變化的域事件。持有該數據副本的組件將會監聽該域事件,並相應地更新他們的本地副本。
控制流程
如我上述所說,控制流程當然是從使用者進入應用核心,再到基礎設施工具,回到應用核心,最後回到使用者手中。但是,類別又是如何組合在一起的呢?哪些類別依賴於哪些類別?我們又該如何組成它們呢?
遵循 Uncle Bob 在他的關於乾淨架構的文章中,我將嘗試用UML風格的圖表來解釋控制流程..
Without a Command/Query Bus
如果我們不使用命令總線,控制器將依賴於應用服務或查詢物件。
在上述圖表中,我們為應用服務使用了一個介面,儘管我們可能會辯論說它實際上並不真正需要,因為應用服務是我們應用程式碼的一部分,我們並不希望將其替換為另一種實現方式,儘管我們可能會對其進行全面的重構。
查詢物件將包含一個優化的查詢,該查詢將簡單地返回一些原始數據以供用戶查看。該數據將在一個DTO中返回,並將注入到一個ViewModel中。這個ViewModel可能包含一些視圖邏輯,並將用於填充視圖。
另一方面,應用服務將包含用例邏輯,也就是我們想在系統中做些什麼時會觸發的邏輯,而不僅僅是查看一些數據。應用服務依賴於 repository,repository 將返回包含需要觸發的邏輯的實體。它也可能依賴於一個領域服務來協調在多個實體中的領域過程,但這種情況幾乎從未發生。
在展開使用案例後,應用服務可能希望通知整個系統該使用案例已經發生,此時它也將依賴事件分派器來觸發事件。
值得注意的是,我們在持久性引擎和 repositories 上都設置了介面。雖然這可能看起來有些多餘,但它們具有不同的目的:
持久性介面是一種在物件關聯對映(ORM)之上的抽象層,因此我們可以在不更改應用程式核心的情況下,更換正在使用的ORM。
repository interface 是對持久性引擎本身的抽象。假設我們想從MySQL切換到MongoDB。持久性介面可以保持一樣,而且,如果我們想繼續使用相同的ORM,甚至持久性適配器也將保持不變。然而,查詢語言完全不同,所以我們可以創建新的 repository,使用相同的持久性機制,實現相同的 repository interface,但是使用MongoDB查詢語言來構建查詢,而不是SQL。
With a Command/Query Bus
在我們的應用程式使用命令/查詢總線的情況下,圖表基本上保持不變,唯一的例外是控制器現在依賴於總線以及一個命令或查詢。它將實例化命令或查詢,並將其傳遞給總線,總線將找到適當的處理器來接收並處理該命令。
在下面的圖表中,命令處理器會使用應用服務。但是,這並不總是必要的,事實上,在大多數情況下,處理器將包含所有用例的邏輯。我們只需要在需要在另一個處理器中重用相同邏輯時,才將邏輯從處理器中提取到一個獨立的應用服務中。
您可能已經注意到,Bus與Command、Query以及Handlers之間並無依賴關係。這是因為他們實際上應該對彼此一無所知,以便提供良好的解耦。Bus將如何知道哪個Handler應該處理哪個Command或Query,應該僅通過配置來設定。
如您所見,在兩種情況下,所有跨越應用程式核心邊界的箭頭,也就是依賴性,都指向內部。如先前所述,這是Ports & Adapters架構、洋蔥架構以及乾淨架構的基本規則。
Conclusion 結論 如往常一樣,我們的目標是擁有一個低耦合、高內聚的程式碼庫,以便我們能夠輕鬆、快速且安全地進行變更。
Plans are worthless, but planning is everything. - Eisenhower 計劃本身毫無價值,但規劃過程卻是一切的關鍵。 - 艾森豪威爾
這張資訊圖表是一個概念圖。了解並理解所有這些概念將有助於我們規劃健康的架構,以及健康的應用程式。
然而:
*The map is not the territory. - Alfred Korzybski * 地圖並非領土。 - 阿爾弗雷德·科爾日布斯基
這些只是指導方針!應用程序就是領域,現實,我們需要應用我們知識的具體用例,這將決定實際架構的外觀! 我們需要理解所有這些模式,但我們也總是需要思考並準確理解我們的應用程式需要什麼,為了解耦和內聚性我們應該走多遠。這個決定可以依賴許多因素,從項目的功能需求開始,但也可以包括像是建立應用程式的時間範圍,應用程式的壽命,開發團隊的經驗等等因素。
就是這樣,這就是我如何理解所有的事情。這就是我在腦海中如何合理化它。
我在後續的文章中進一步擴展了這些想法:不僅僅是同心層。
然而,我們該如何在程式碼庫中明確地呈現所有這些內容呢?這將是我接下來的文章主題之一:如何在程式碼中反映架構和領域。